数据解析子模块
该子模块的逻辑比较简单,就是接收爬虫子模块传来的html代码,然后调用python代码后,返回所需要的对象,进一步包装后写入到数据访问层。
代码实现的话,先构建一个python帮助类,这里使用了boost::python
class PythonHelper
{
public:
static void Init()
{
Py_Initialize();
}
//根据python文件名,python函数名获取相应的函数对象
static boost::python::object GetFunc(const std::string &module, const std::string &func_name)
{
static auto main_namespace_ = []()->boost::python::object&
{
static boost::python::object main_module = boost::python::import("__main__");
static boost::python::object obj = main_module.attr("__dict__");
return obj;
};
static boost::python::object& main_namespace = main_namespace_();
std::string filename("../py/");
filename += module;
filename += ".py";
boost::python::exec_file(filename.c_str(), main_namespace, main_namespace);
return main_namespace[func_name];
}
//运行python脚本的过程中发生异常时,输出日志
static void WriteErrorLog(Common::Logger& log)
{
using namespace boost::python;
using namespace boost;
PyObject *exc, *val, *tb;
object formatted_list, formatted;
PyErr_Fetch(&exc, &val, &tb);
handle<> hexc(exc), hval(allow_null(val)), htb(allow_null(tb));
object traceback(import("traceback"));
object format_exception(traceback.attr("format_exception"));
formatted_list = format_exception(hexc, hval, htb);
formatted = boost::python::str("\t\n").join(formatted_list);
log.fatal(extract<std::string>(formatted));
}
private:
PythonHelper(void){}
~PythonHelper(void){}
};
其中Init()进行初始化操作,GetFunc()传入python脚本的文件(模块)名和函数名,返回相应的函数对象,而WriteErrorLog()允许在捕获到python异常时写入异常信息。
然后就着手编写具体的业务了,整个解析类的结构如下:
enum class TencentJobInfoParseResult
{
Continue,//告诉clawer继续工作
Stop,//告诉clawer已访问到末尾,该停下了
Pass,//属于个例的错误,跳过
Retry,//属于可以重试的错误
Error,//遇到普通错误
Fatal//遇到致命错误
};
//负责解析腾讯招聘的网页信息
class TencentJobInfoParser
{
public:
//解析列表页面里的职位清单
static TencentJobInfoParseResult ParseJobList(const std::string& html,
std::vector<Model::Job*>& job_list,
const Base::Date& end_date);
//解析列表页面里的职位清单的hash值
static TencentJobInfoParseResult ParseJobListHash(const std::string& html, uint64_t& hash);
//解析列表页面里的职位清单,获取所有的职位日期
static TencentJobInfoParseResult ParseJobDates(const std::string& html, std::vector<Base::Date>& job_dates);
//只获取第一和最后一个item的日期
static TencentJobInfoParseResult ParseJobDates(const std::string& html, Base::Date& first_item_date, Base::Date& last_item_date);
//解析详情页面里的职位详细信息
static TencentJobInfoParseResult ParseJobDetail(Model::Job& job,const std::string& html);
static void Init();
static Common::Logger& log;
private:
TencentJobInfoParser(void){}
~TencentJobInfoParser(void){}
};
拿ParseJobList()解析列表页的方法展示一下解析的过程吧:
首先是C++代码:
TencentJobInfoParseResult TencentJobInfoParser::ParseJobList(const std::string& html,
std::vector<Model::Job*>& job_list,
const Base::Date& end_date)
{
using namespace boost::python;
using Common::PythonHelper;
using Common::DateHelper;
using Base::Date;
try
{
static const std::string kTruncatedStr("truncated");
if (kTruncatedStr.compare(html)==0)
{
return TencentJobInfoParseResult::Stop;
}
//由于解析html的时间相对于抓取html的时间可以忽略不计
//再加上两次http请求间必须有延迟(频率过高可能被防火墙拉黑)
//所以此处的重点不在于执行效率,为了灵活起见嵌入python脚本
//调用parser.py中的parseTencentJobList函数,将来若页面结构发生变化只需要调整py文件
//此处将函数对象设为static,这样第一次调用GetFunc方法时这个对象会被保存起来供下次使用,避免重复的文件访问
static object func = PythonHelper::GetFunc("parser", "parseTencentJobList");
object ret = func(html);
object list = ret[0];
bool has_next = extract<bool>(ret[1]);
if (!list.is_none())
{
int length = len(list);
if (length == 0)
{
//有列表,但没数据,说明已经抓到底了
return TencentJobInfoParseResult::Stop;
}
//正常返回
for (int i = 0; i < length; i++)
{
using std::string;
object obj = list[i];
string url, title, type, location, date_str;
int id, hiring_number;
id = extract<int>(obj[0]);
title = extract<string>(obj[1]);
type = extract<string>(obj[2]);
hiring_number = extract<int>(obj[3]);
location = extract<string>(obj[4]);
date_str = extract<string>(obj[5]);
try
{
Date date = DateHelper::ToDate(date_str);
if (date<end_date)
{
//日期超越抓取范围,停止抓取任务
return TencentJobInfoParseResult::Stop;
}
//将数据写入数据访问层,同时将实体类对象指针写入列表结果
job_list.emplace_back(&Model::Job::Add(id, title, type, hiring_number, location, date));
}
catch (std::exception& e)
{
log.error(fmt("解析日期时发生异常[%1%,%2%,%3%]:%4%")%id %title % date_str % e.what());
continue;//当做是个别现象,跳过这一行
}
}
return has_next?TencentJobInfoParseResult::Continue : TencentJobInfoParseResult::Stop;
}
else
{
return TencentJobInfoParseResult::Error;
}
}
catch (boost::python::error_already_set&)
{
PythonHelper::WriteErrorLog(log);
return TencentJobInfoParseResult::Fatal;
}
}
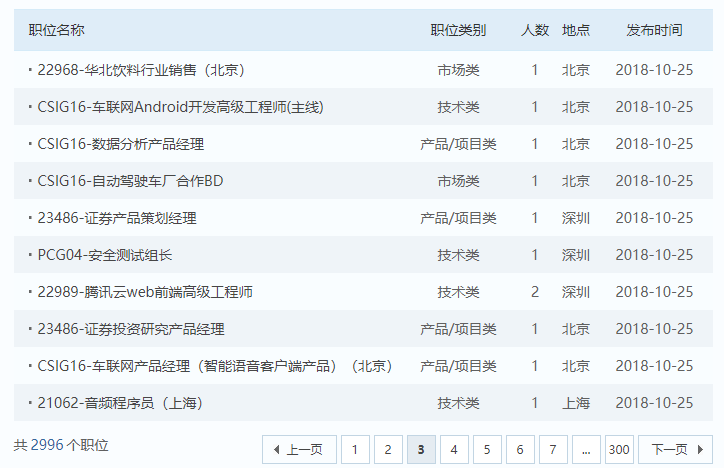
假设是所解析的如图所示列表页,程序调用解析html的python脚本后,会得到一个python的list对象。list对象保存了每行的数据,我们分别将其还原成id,title(标题),type(种类),hiring_number(招聘人数),location(地点),date_str(发布日期)。
id = extract<int>(obj[0]);
title = extract<string>(obj[1]);
type = extract<string>(obj[2]);
hiring_number = extract<int>(obj[3]);
location = extract<string>(obj[4]);
date_str = extract<string>(obj[5]);
然后写入职位信息到数据访问层,如果发现职位信息超过抓取范围,则会返回一个标识,标识应停止任务:
Date date = DateHelper::ToDate(date_str);
if (date<end_date)
{
//日期超越抓取范围,停止抓取任务
return TencentJobInfoParseResult::Stop;
}
job_list.emplace_back(&Model::Job::Add(id, title, type, hiring_number, location, date));
注意,经过这一步抓取后职位对象的数据还不完整,因为没有访问到详情页,并不知道里面的内容(工作职责和工作要求)是什么,需要后面再做进一步的数据填充。
C++的代码就是这些,接下来是对应的python脚本的代码:
def parseTencentJobList(html):
tree=etree.HTML(html)
table=tree.xpath("//div[@id='position']//table[@class='tablelist']")
#若table长度为0,说明未能成功解析到期待的页面,返回None
if len(table)==0:
return None
list=[]
has_next=len(table[0].xpath(".//a[@id='next' and @class='noactive']"))==0
nodes=table[0].xpath("tr[@class='even' or @class='odd']")
for node in nodes:
tds=node.findall("./td")
a=tds[0].find("./a")
url=a.get("href")
m=re.search(r"id=(\d+)",url) #利用正则表达式从href的url中解析出职位的id
id=int(m.group(1))
title=myEncode(a.text)
type=myEncode(tds[1].text)
hiring_number=int(tds[2].text)
location=myEncode(tds[3].text)
date=myEncode(tds[4].text)
list.append((id,title,type,hiring_number,location,date))
return list,has_next
其中职位id没有直接展现出来,我是利用正则表达式从href里的url里提取出来的。
整个代码完全是利用xpath对网页元素进行解析,比较死板,任何页面结构上的小改动都有可能导致该代码失效。
好在解析部分的代码用python实现,更新代码所花费的代价相对比较小。
详情页的解析等等原理差不多,这里就不重复了。